
Regardless of the utility of huge language fashions (LLMs) throughout numerous duties and situations, researchers need assistance to guage LLMs correctly in numerous conditions. They use LLMs to examine their responses, however an answer should be discovered. This methodology is proscribed as a result of there aren’t sufficient benchmarks, and it typically requires plenty of human enter. They urgently want higher methods to check how properly LLMs can consider issues in all conditions, particularly when customers outline new situations.
LLMs have superior considerably, demonstrating spectacular efficiency throughout numerous duties. Nonetheless, evaluating their outputs presents advanced challenges. Present approaches primarily depend on automated metrics, typically using LLMs for analysis. Whereas some capabilities bear rigorous meta-evaluation, requiring pricey human-annotated datasets, many functions want extra scrutiny, resulting in potential unreliability in LLMs as evaluators.
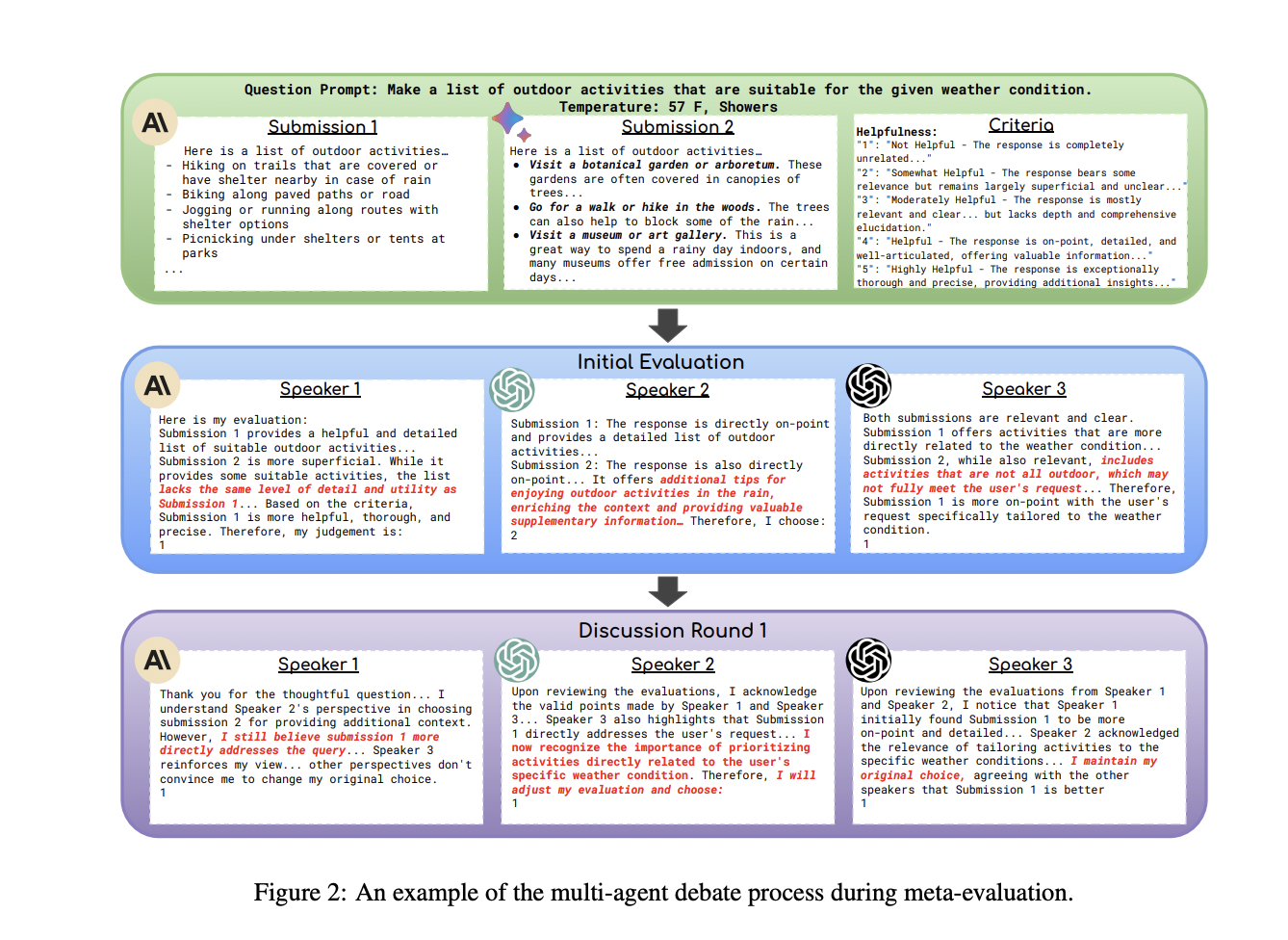
Researchers from Shanghai Jiao Tong College, Carnegie Mellon College, Shanghai Synthetic Intelligence Laboratory, and Generative AI Analysis Lab (GAIR) introduce SCALEEVAL, a meta-evaluation framework using a number of communicative LLM brokers with an agent-debate method. This method facilitates multi-round discussions, aiding human annotators in figuring out essentially the most proficient LLMs for analysis. This method considerably reduces the burden on annotators, particularly in situations the place in depth annotations had been historically crucial for meta-evaluation.
SCALEEVAL leverages multi-agent debate for dependable meta-evaluation of LLMs. Within the meta-evaluation course of, LLM brokers interact in rounds of discussions to evaluate responses primarily based on user-defined standards. This reduces the reliance on in depth human annotation and ensures scalability. The analysis framework entails pairwise response comparisons, specializing in LLMs like gpt-3.5-turbo. Human skilled meta-meta analysis validates the proposed methodology’s reliability by making use of the agent-debate-assisted and human skilled annotation protocols. This method balances effectivity with human judgment for correct and well timed assessments.
Research reveal that LLMs’ efficiency as evaluators tends to say no when particular letters in standards prompts are masked. The removing of guiding phrases additional diminishes effectiveness. Gpt-4-turbo and gpt-3.5-turbo exhibit resilience, sustaining constant settlement charges throughout standards codecs. In distinction, Claude-2 shows confusion and reluctance, particularly with adversarial prompts, rejecting roughly half of the questions. The examined LLMs wrestle with substituted standards data, indicating room for enchancment of their design and utility regardless of their superior capabilities.
In conclusion, The researchers have launched SCALEEVAL, a scalable meta-evaluation framework using agent-debate help to evaluate LLMs as evaluators. This proposal addresses the inefficiencies of typical, resource-intensive meta-evaluation strategies, that are essential as LLM utilization grows. The examine not solely validates the reliability of SCALEEVAL but in addition illuminates the capabilities and limitations of LLMs in various situations. This work contributes to advancing scalable options for evaluating LLMs, which is significant for his or her increasing functions.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and Google Information. Be part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our Telegram Channel
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.

.png)
