Copying from PDFs generally is a difficult job. When pasting the copied textual content or knowledge, usually the formatting should be fastened, with spacing, alignment, and particular characters in every single place. Cleansing it up can take ages.
Extracting content material from PDF information generally is a trouble, however with the appropriate instruments and methods, it may be carried out with ease. This complete information will stroll you thru completely different strategies to repeat numerous sorts of content material from PDF information, making the extraction course of sooner and extra environment friendly.
1. Use Adobe Acrobat Reader’s Choose device to repeat textual content
Adobe Acrobat Reader is among the many most in style PDF viewers on the market. In case you don’t need to set up or join further software program, use Acrobat Reader’s built-in textual content choice device.
Observe these steps to get began:
- Open your PDF in Adobe Acrobat Reader.
- Click on the “Choose Instrument” button (arrow icon) within the toolbar to spotlight textual content within the PDF.
- Click on and drag to pick out the textual content. You possibly can choose textual content throughout a number of pages if wanted.
- Spotlight the textual content, right-click, choose “Copy”, or use Ctrl+C on Home windows or Command+C on Mac.
- Paste the textual content utilizing Ctrl+V or Cmd+V.
This technique is good for easy PDFs comprised largely of textual content. You possibly can manually copy the content material in segments and paste it into your goal doc. Not like different PDF readers, Acrobat Reader preserves the formatting effectively.
Acrobat Reader struggles with advanced PDFs — these with a number of columns and pictures blended with textual content, tables, and textual content on coloured backgrounds. The copied textual content may lose formatting and be pasted as plain textual content, needing handbook cleanup or modifying later.
It will not be ultimate for bulk textual content extraction from PDFs. For instance, processing vendor contracts and extracting key phrases and clauses from tons of of PDFs may be tedious and time-consuming. Scanned pages are much more tough to repeat textual content from.
General, Acrobat Reader’s built-in copy textual content function works effectively for easy PDFs or rapidly grabbing textual content from nearly any PDF.
Do you simply need to copy knowledge from a bunch of PDFs? MS Excel’s Get Knowledge function works wonders. It could mechanically extract tables and knowledge from PDF information into Excel spreadsheets.

Observe these easy steps:
- Open Excel and go to the Knowledge tab.
- Click on Get Knowledge > From File> From PDF.
- Choose the PDF file(s) you want to import knowledge from. Excel will mechanically detect and extract tables from the PDF doc(s).
- The Import Knowledge dialog field shows a preview of the information. Select the desk(s) you want to import and click on Load.
- The extracted PDF knowledge might be inserted into the spreadsheet as a desk, permitting for clear knowledge for evaluation.
The info extraction works effectively for textual PDFs. You possibly can choose a desk or a number of tables to import from a number of PDF information. Excel can intelligently separate the information into rows and columns. It additionally permits customers so as to add filters or remodel the imported knowledge inside Excel. This makes it simple to rapidly get usable knowledge out of PDFs into Excel for additional evaluation and dashboarding.
Nevertheless, Excel struggles to extract the information for scanned paperwork or PDFs precisely with advanced layouts, comparable to textual content columns or textual content over photographs. It really works finest with textual PDFs with clearly outlined knowledge tables and grid-like layouts. In case your PDF knowledge is neatly organized in tables, utilizing Excel can prevent tons of handbook copying, pasting, and reformatting work.
You will want extra superior knowledge extraction capabilities for unstructured knowledge locked in scanned paperwork or advanced studies.
3. Open the PDF utilizing Google Docs or MS Phrase
Google Docs and Microsoft Phrase are two of the most well-liked textual content processors. They now have built-in optical character recognition (OCR) capabilities to transform photographs and scanned paperwork into editable textual content.
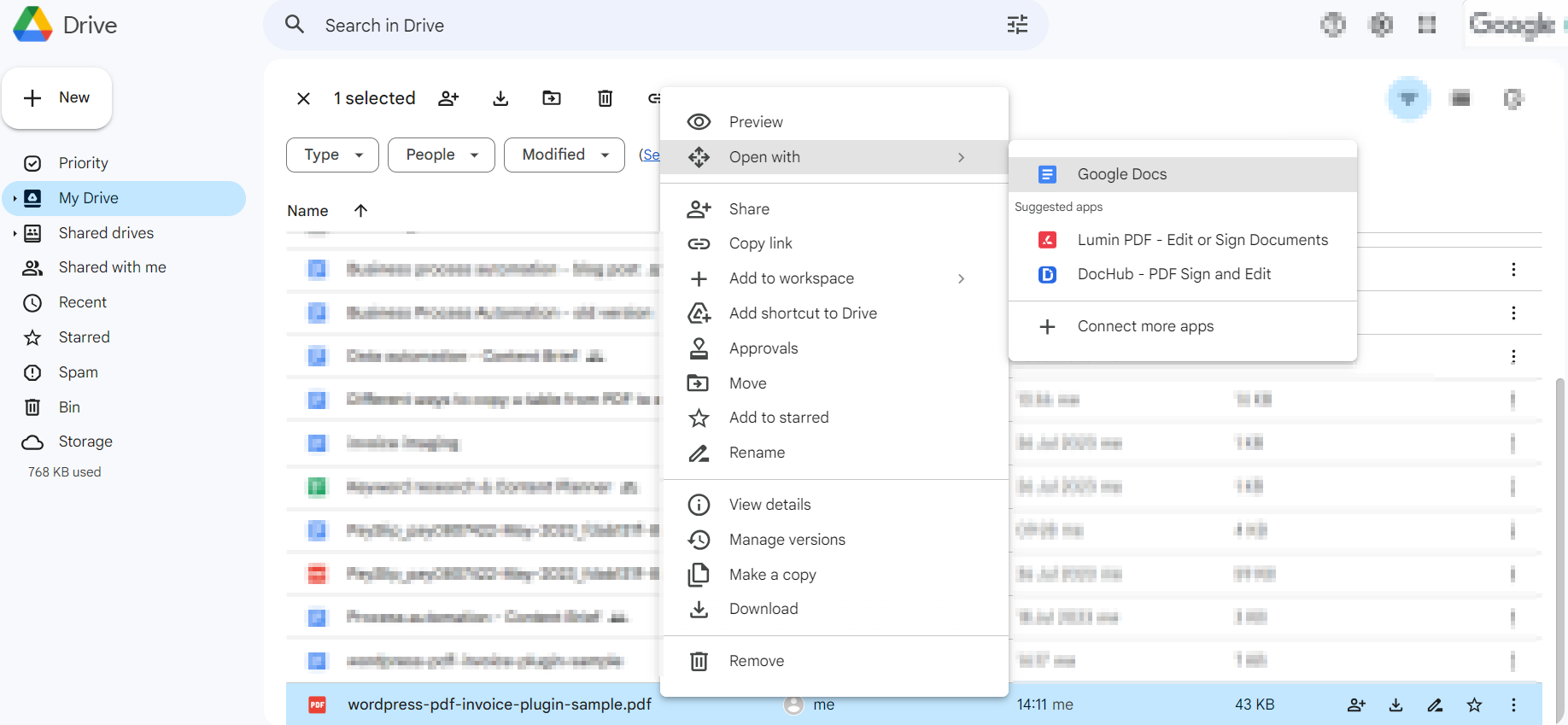
Right here’s how one can reap the benefits of this:
- Open Google Docs or Phrase and go to File> Open.
- Choose your PDF file. Google Docs/Phrase will extract the textual content and pictures from the PDF into a brand new doc.
- Copy or edit the extracted textual content as wanted.
- Paste the copied textual content into another software or doc.
Word: Chances are you’ll want to just accept compatibility mode prompts earlier than opening the PDF.
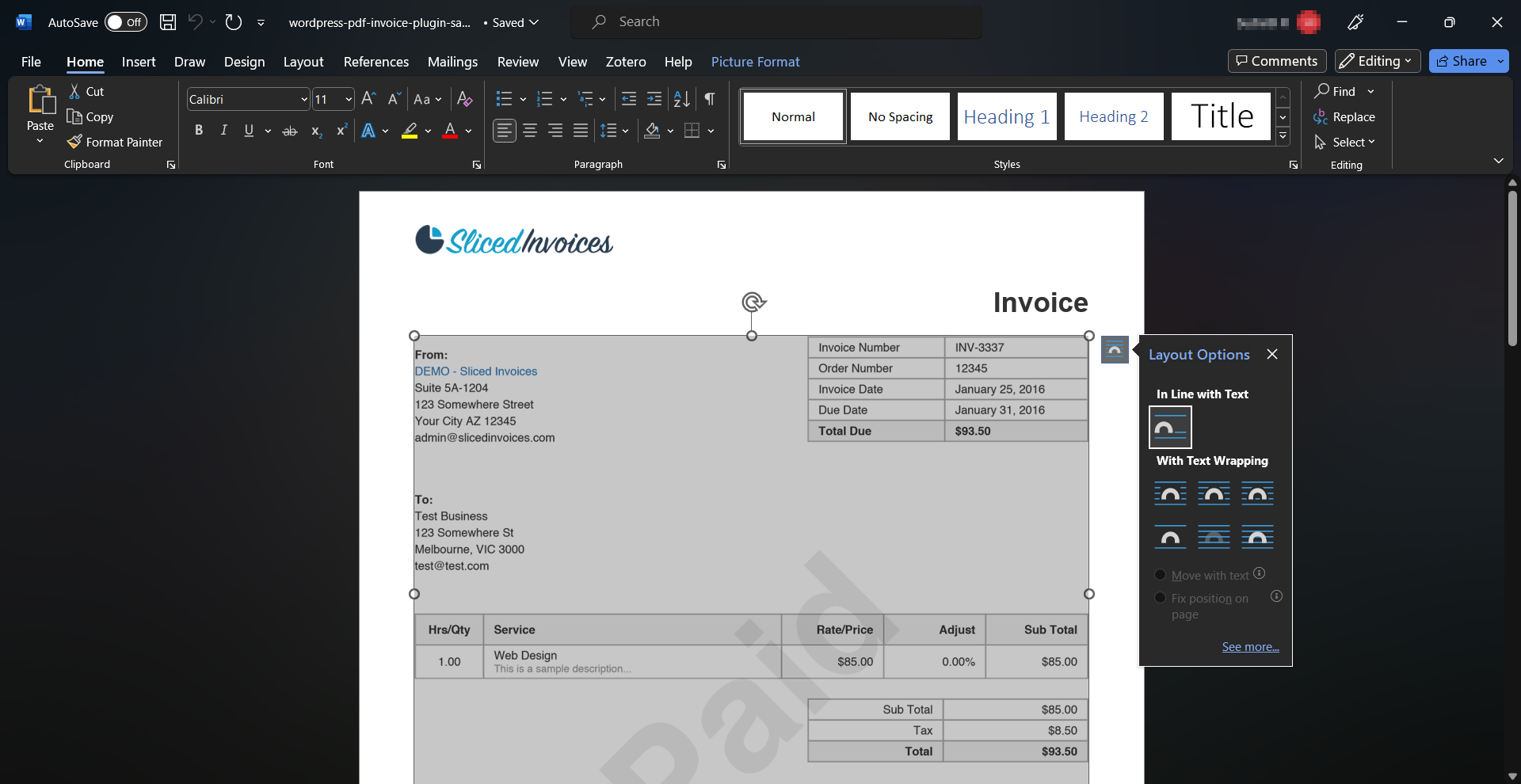
The extracted textual content retains fundamental formatting and is editable inside Google Docs or Phrase, permitting for cleansing up the textual content, modifying typos, or making different modifications earlier than copying it.
Complicated PDF layouts with a number of columns and text-over photographs can pose challenges throughout conversion. The output doc could have formatting points or textual content within the flawed order. So, whereas handy for easy PDFs, Google Docs and Phrase could battle with scanned or intricately designed paperwork.
General, utilizing Google Docs and Phrase to open and duplicate textual content from PDFs works effectively for day-to-day wants. Nevertheless, extra highly effective PDF extraction instruments are advisable for superior knowledge extraction from advanced studies or bulk processing of contracts, authorized paperwork, and different paperwork.
Devoted instruments with OCR (Optical Character Recognition) capabilities can extract textual content from scanned paperwork or image-based PDFs. These handy options mean you can add your PDF file and obtain the extracted textual content again immediately with none want for software program set up.
Among the in style on-line OCR instruments embody:
Quite a few easy-to-use conversion instruments obtainable on the net can simplify the method of extracting textual content from a PDF doc. These instruments can deal with a wide range of output codecs and can even make an image-based PDF searchable.
To make use of an internet converter:
- Go to the device’s web site.
- Add your PDF file or enter the URL the place it’s hosted.
- Select the output format — DOC, TXT, XLS, XLSX, JSON, or CSV.
- Click on “Convert” and look ahead to the extraction of all textual content to complete.
- Obtain the output file containing the extracted textual content and duplicate the required textual content.
Most on-line converters supply some fundamental utilization without cost. Nevertheless, sure superior options and elevated limits could require a paid subscription. Additionally, be conscious of privateness insurance policies earlier than importing delicate knowledge.
Whereas handy, these instruments can falter with advanced desk layouts in PDFs. Conventional OCR instruments usually battle to precisely extract textual content from advanced layouts with textual content columns, photographs, and different parts. The extracted knowledge could require in depth handbook cleanup earlier than getting used for evaluation or reporting. Moreover, most on-line OCR converters have file dimension and month-to-month web page limits that may rapidly get exhausted when processing giant volumes of paperwork.
Nanonets is an AI-powered doc processing platform with superior OCR and automation capabilities to precisely extract textual content and knowledge from PDFs and scanned paperwork.

The important thing capabilities
It could deal with advanced layouts with a number of textual content columns, photographs, tables, and different parts precisely. Nanonets leverages machine studying (ML) and pure language processing (NLP) to “see” and “perceive” doc buildings. This allows textual content and knowledge extraction with context, sustaining the proper studying order and knowledge relationships.
With built-in validation and approval workflows, you possibly can guarantee high-quality output earlier than exporting the extracted knowledge. Nanonets additionally offers detailed accuracy studies to watch OCR high quality throughout numerous doc varieties.
An instance
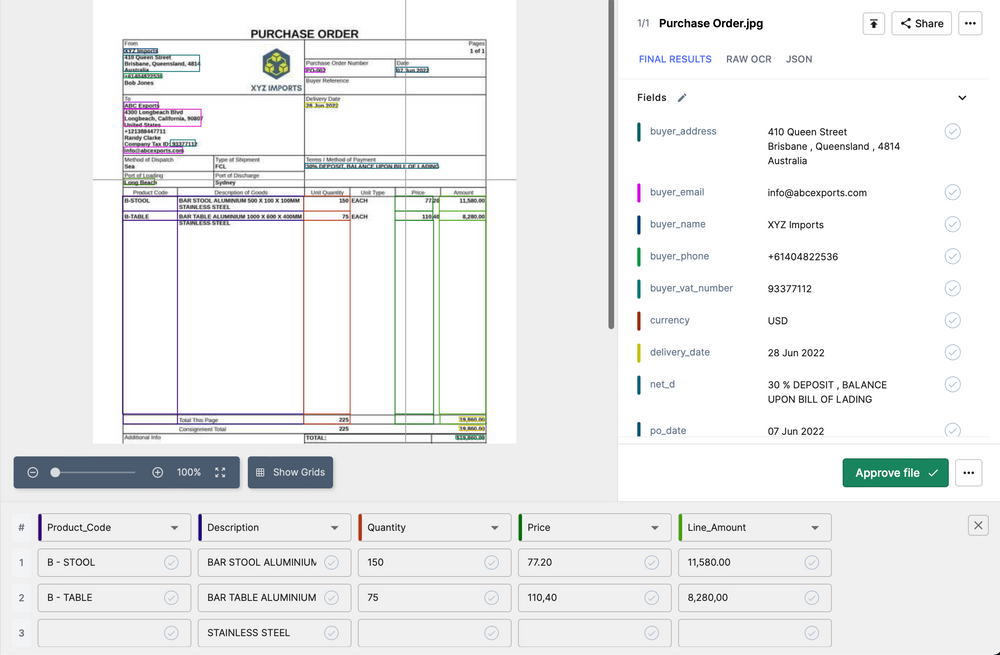
Suppose you run a recruitment agency that processes tons of of PDFs each day. Your group should manually extract names, electronic mail addresses, telephone numbers, expertise, and expertise from resumes and functions. With Nanonets, you possibly can construct an automatic pipeline to OCR PDFs and extract structured knowledge from resumes at scale. The platform understands resume layouts and extracts correct knowledge fields, enabling quick processing of excessive volumes of paperwork with minimal handbook work.
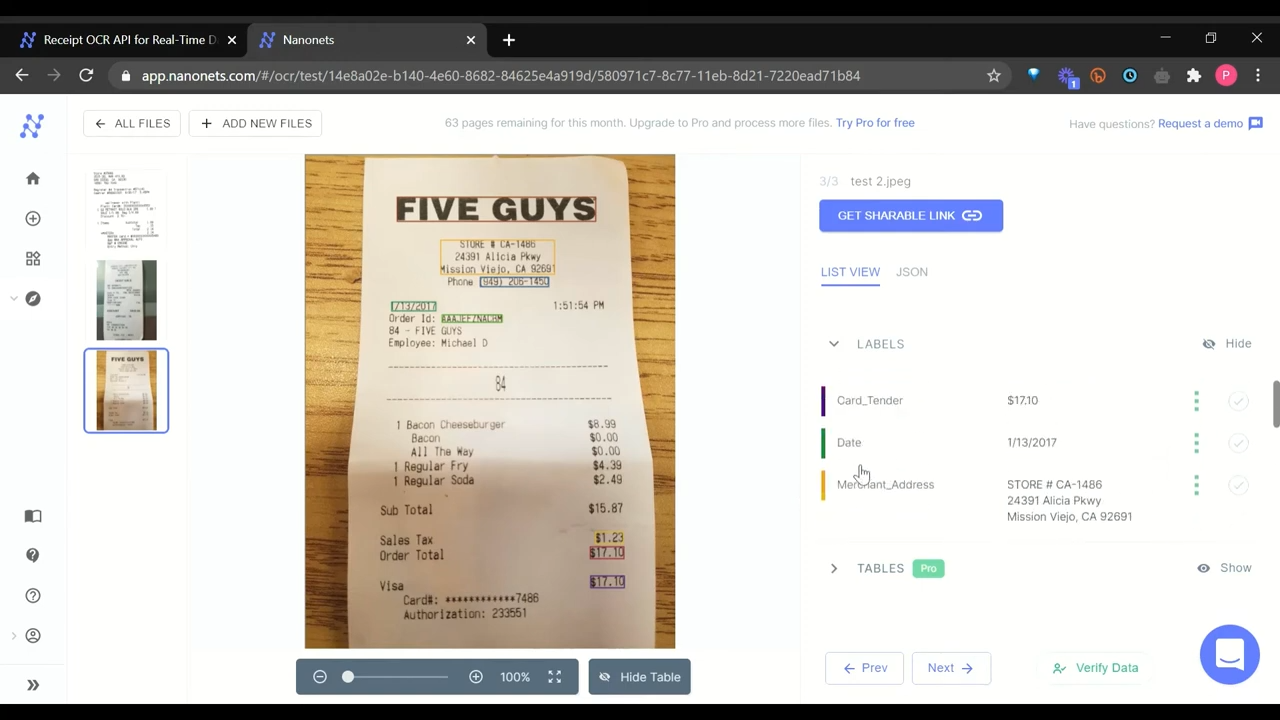
As well as, Nanonets offers a strong API and integration ecosystem that lets you join it to your present methods and workflows seamlessly. You possibly can arrange auto-import of paperwork from Gmail, Google Drive, OneDrive, and Dropbox. Integrations with instruments like Microsoft Dynamics, QuickBooks, and Xero mean you can route extracted knowledge to your corporation methods mechanically. It additionally integrates with the favored workflow automation platform Zapier, which connects over 5,000 apps.
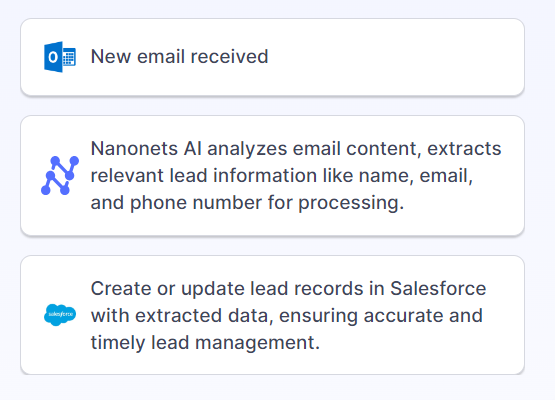
For instance, you possibly can create an automatic workflow that OCRs resume PDFs uploaded to your Google Drive, extracts names, emails, and telephone numbers right into a Google Sheet, after which makes use of Zapier so as to add these contacts to your CRM and assign duties to gross sales representatives to observe up with high-potential candidates.
It could course of paperwork in numerous currencies, languages, layouts, and codecs with out shedding context. The AI learns from coaching knowledge and handbook interventions, bettering its accuracy.
get began?
Add a pattern set of 5-10 paperwork, annotate the textual content you want to extract, and Nanonets will mechanically construct a customized AI mannequin tailor-made to your paperwork. It could course of hundreds of pages monthly whereas sustaining an accuracy price of over 95%.
The pricing for Nanonets is usage-based, permitting you to begin small and scale up as your wants develop. The primary 500 pages are free, and also you’ll have entry to 3 AI fashions, enabling you to check Nanonets on a number of doc varieties earlier than committing.
Ultimate ideas
Copying and pasting from PDFs would not should be a chore. You possibly can simplify and streamline the method with the appropriate instruments and methods.
The most effective strategy is determined by your particular wants and paperwork. Assess your PDFs’ complexity, workflow wants, knowledge privateness insurance policies, and extra. Discovering the answer that checks all of the containers on your scenario is essential to long-term effectivity. The purpose is to get rid of the handbook drudgery of copying PDF textual content. Whether or not you deal with just a few paperwork a month or course of hundreds of pages each day, options exist to make your life simpler.


