
Textual content-to-image (T2I) era is a quickly evolving area inside laptop imaginative and prescient and synthetic intelligence. It entails creating visible photographs from textual descriptions mixing pure language processing and graphic visualization domains. This interdisciplinary method has vital implications for numerous functions, together with digital artwork, design, and digital actuality.
Numerous strategies have been proposed for controllable text-to-image era, together with ControlNet, layout-to-image strategies, and picture modifying. Massive language fashions (LLMs) like GPT-4 and Llama have capabilities in pure language processing and are being adopted as brokers for complicated duties. Nonetheless, they need to enhance when coping with complicated situations involving a number of objects and their intricate relationships. This limitation highlights the necessity for a extra subtle method to precisely decoding and visualizing elaborate textual descriptions.
Researchers from Tsinghua College, the College of Hong Kong, and Noah’s Ark Lab launched CompAgent. This technique leverages an LLM agent for compositional text-to-image era. CompAgent stands out by adopting a divide-and-conquer technique, enhancing picture synthesis controllability for complicated textual content prompts.
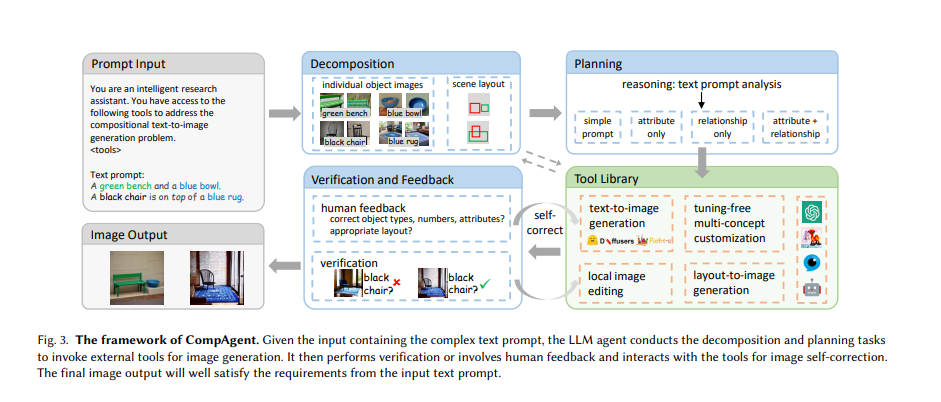
CompAgent makes use of a tuning-free multi-concept customization device to generate photographs based mostly on current object photographs and enter prompts, a layout-to-image era device to handle object relationships inside a scene, and a neighborhood picture modifying device for exact attribute correction utilizing segmentation masks and cross-attention modifying. The agent selects probably the most appropriate device based mostly on the textual content immediate’s attributes and relationships. Verification and suggestions, together with human enter, are integral for making certain attribute correctness and adjusting scene layouts. This complete method, combining a number of instruments and verification processes, enhances the aptitude of text-to-image era, guaranteeing correct and contextually related picture outputs.

CompAgent has proven distinctive efficiency in producing photographs that precisely symbolize complicated textual content prompts. It achieves a 48.63% 3-in-1 metric, surpassing earlier strategies by greater than 7%. It has reached over 10% enchancment in compositional text-to-image era on T2I-CompBench, a benchmark for open-world compositional text-to-image era. This success illustrates CompAgent’s potential to successfully tackle the challenges of object kind, amount, attribute binding, and relationship illustration in picture era.
In conclusion, CompAgent represents a big achievement in text-to-image era. It solves the issue of producing photographs from complicated textual content prompts and opens new avenues for inventive and sensible functions. Its potential to precisely render a number of objects with their attributes and relationships in a single picture is a testomony to the developments in AI-driven picture synthesis. It addresses current challenges within the area and paves the best way for brand new prospects in digital imagery and AI integration.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and Google Information. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our Telegram Channel
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


