
A key problem in text-to-music era utilizing diffusion fashions is controlling pre-trained text-to-music diffusion fashions at inference time. Whereas efficient, these fashions can solely generally produce fine-grained and stylized musical outputs. The problem stems from their complexity, which normally requires refined methods for fine-tuning and manipulation to attain particular musical types or traits. This limitation turns into particularly evident in complicated audio duties.
Analysis within the discipline of computer-generated music has made vital progress. Whereas language model-based approaches generate audio sequentially, diffusion fashions create frequency-domain audio representations. Textual content is usually used for controlling diffusion fashions, however this methodology wants extra exact management. Superior management is achievable by fine-tuning current fashions or incorporating exterior rewards, with inference-time strategies gaining recognition for particular object manipulation. Nevertheless, strategies utilizing pre-trained classifiers for steering have limitations in expressiveness and effectivity. Although optimization by means of diffusion sampling exhibits promise, it faces challenges in detailed management, necessitating improved options for environment friendly and exact music era.
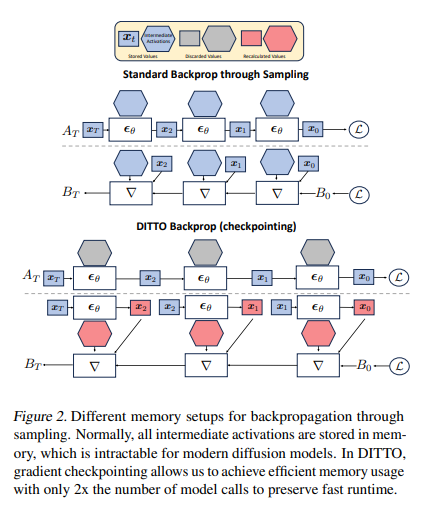
A staff of researchers on the College of California, San Diego, and Adobe Analysis has proposed the “Diffusion Inference-Time T-Optimization” (DITTO) framework, a novel strategy for controlling pre-trained text-to-music diffusion fashions. DITTO optimizes preliminary noise latents at inference time to supply particular, stylized outputs and employs gradient checkpointing for reminiscence effectivity. It may be utilized to numerous time-dependent music era duties.
Researchers centered on enhancing DITTO’s capabilities utilizing a wealthy dataset comprising 1800 hours of licensed instrumental music with style, temper, and tempo tags for coaching. The dataset’s lack of free-form textual content descriptions led to class-conditional textual content management for international musical type. The Wikifonia Lead-Sheet Dataset, with 380 public-domain samples, was employed for melody management. The analysis additionally included handcrafted depth curves and musical construction matrices.
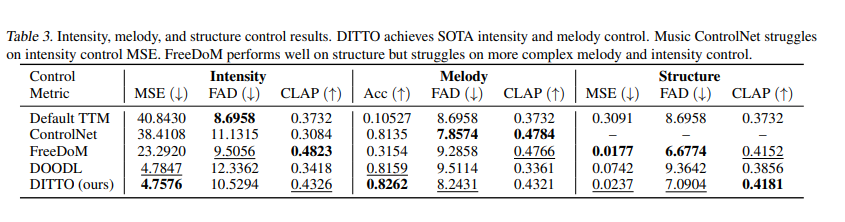
Evaluations utilized the MusicCaps Dataset, that includes 5K clips with textual content descriptions. The Frechet Audio Distance (FAD) with VGGish spine and the CLAP rating was essential in measuring the efficiency, guaranteeing the generated music was intently aligned with the baseline recordings and textual content captions. Outcomes confirmed that DITTO outperforms different strategies like MultiDiffusion, FreeDoM, and Music ControlNet relating to management, audio high quality, and computational effectivity.
DITTO represents a notable development in text-to-music era. It affords a versatile and environment friendly methodology for controlling pre-trained diffusion fashions, enabling the creation of complicated and stylized musical items. Its capacity to fine-tune outputs with out in depth retraining or giant datasets is a big growth in music era know-how.
Try the Paper and Mission. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our Telegram Channel
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.

