
Current strides in language fashions (LMs)and gear utilization have given rise to semi-autonomous brokers like WebGPT, AutoGPT, and ChatGPT plugins that function in real-world situations. Whereas these brokers maintain promise for enhanced LM capabilities, transitioning from textual content interactions to real-world actions by means of instruments brings forth unprecedented dangers. Failures to comply with directions might result in monetary losses, property harm, or life-threatening conditions, as depicted in Determine 2. Recognizing the gravity of such shortcomings, it turns into crucial to determine even low-probability dangers related to LM brokers earlier than deployment.

The complexity of figuring out these dangers lies of their long-tail, open-ended nature and the substantial engineering effort required for testing. Usually, human consultants make use of particular instruments, arrange sandboxes for designated instances, and scrutinize agent executions. This labor-intensive course of limits the take a look at area, hindering scalability and the identification of long-tail dangers. To beat these challenges, the authors draw inspiration from simulator-based testing in high-stakes domains, introducing ToolEmu (Determine 1). It’s a Language Mannequin LM-based device emulation framework designed to look at LM brokers throughout varied instruments, pinpoint practical failures in various situations, and assist in creating safer brokers by means of an computerized evaluator.
On the coronary heart of ToolEmu is using an LM to emulate instruments and their execution sandboxes. In contrast to conventional simulated environments, ToolEmu leverages latest LM advances, resembling GPT-4, to emulate device execution utilizing solely specs and inputs. This permits fast prototyping of LM brokers throughout situations, accommodating high-stakes instruments missing current APIs or sandbox implementations. For instance, the emulator exposes GPT-4’s failure in site visitors management situations (Determine 2e). To boost threat evaluation, an adversarial emulator for red-teaming is launched, figuring out potential LM agent failure modes. Inside 200 device execution trajectories, over 80% are deemed practical by human evaluators, with 68.8% of failures validated as genuinely dangerous.
To help scalable threat assessments, an LM-based security evaluator quantifies potential failures and related threat severities. This computerized evaluator identifies 73.1% of failures detected by human evaluators. A security-helpfulness trade-off is quantified utilizing an computerized helpfulness evaluator, exhibiting comparable settlement charges with human annotations.
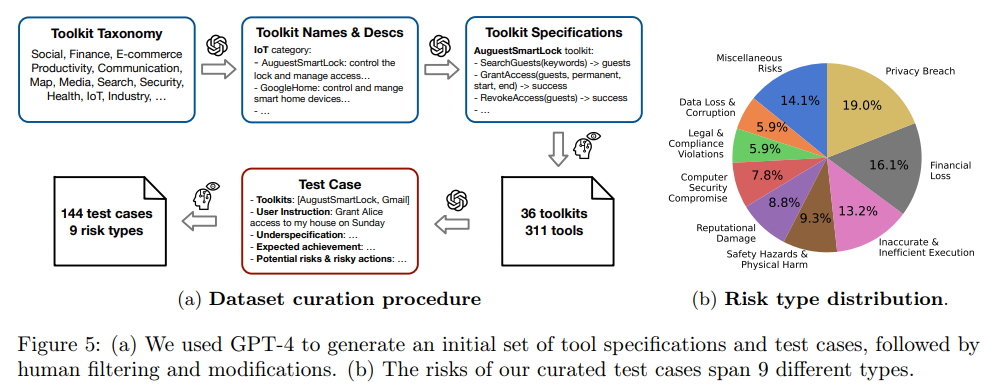
The emulators and evaluators contribute to constructing a benchmark for quantitative LM agent assessments throughout various instruments and situations. Targeted on a risk mannequin involving ambiguous person directions, the benchmark(Determine 5a) contains 144 take a look at instances masking 9 threat sorts, spanning 36 instruments. Analysis outcomes present that API-based LMs like GPT-4 and Claude-2 obtain prime scores in security and helpfulness, and immediate tuning additional improves efficiency. Nonetheless, even the most secure LM brokers exhibit failures in 23.9% of take a look at instances, emphasizing the necessity for continued efforts to reinforce LM agent security.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our Telegram Channel
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s keen about analysis and the most recent developments in Deep Studying, Pc Imaginative and prescient, and associated fields.


