
Activity-agnostic mannequin pre-training is now the norm in Pure Language Processing, pushed by the current revolution in massive language fashions (LLMs) like ChatGPT. These fashions showcase proficiency in tackling intricate reasoning duties, adhering to directions, and serving because the spine for extensively used AI assistants. Their success is attributed to a constant enhancement in efficiency with elevated capability or pre-training knowledge. The exceptional scaling conduct of those fashions, particularly when coupled with Transformer architectures, prompts an exploration past textual content. The inquiry revolves round whether or not making use of an autoregressive goal to Imaginative and prescient Transformers (ViT) can obtain aggressive efficiency and scalability just like that of LLMs, marking an preliminary step in the direction of generalizing findings past language modeling.
The appliance of autoregressive fashions spans various domains, specializing in language modeling and speech in current literature. Investigations discover enhancing picture autoregressive fashions by tailor-made architectures like convolution networks and transformers. Scaling with elevated computing and knowledge yields steady enhancements. The self-supervised pre-training methodologies embody contrastive aims and generative approaches equivalent to autoencoders and GANs. The importance of scale in pre-training visible options is underscored, drawing comparisons to works like DINOv2 and revealing insights into the scaling regulation noticed in language modeling.
The researchers from Apple current Autoregressive Picture Fashions (AIM) as a large-scale pretraining method for visible options. Constructing on prior work like iGPT, they leverage imaginative and prescient transformers, intensive internet knowledge collections, and up to date developments in LLM pre-training. AIM introduces two key modifications: adopting prefix consideration for bidirectional self-attention and using a closely parameterized token-level prediction head impressed by contrastive studying. These changes improve characteristic high quality with out substantial coaching overhead, aligning AIM’s methodology with current LLM coaching approaches devoid of stability-inducing strategies utilized in supervised or self-supervised strategies.
AIM adopts the Imaginative and prescient Transformer structure, prioritizing width growth for mannequin capability scaling. AIM employs causal masks for self-attention layers throughout pre-training, introducing a prefix consideration mechanism for downstream duties. The structure incorporates Multilayer Perceptron (MLP) prediction heads, avoiding stability-inducing mechanisms. Sinusoidal positional embeddings are added, and AIM makes use of bfloat16 precision with the AdamW optimizer. Downstream adaptation entails mounted mannequin weights and a spotlight pooling for international descriptors, enhancing efficiency with minimal extra parameters.
AIM is in contrast with state-of-the-art strategies throughout 15 various benchmarks. AIM outperforms generative counterparts, equivalent to BEiT and MAE-H, and surpasses MAE-2B pre-trained on IG-3B, a personal dataset. AIM demonstrates aggressive efficiency with joint embedding strategies like DINO, iBOT, and DINOv2, reaching excessive accuracy utilizing easier pre-training with out counting on intensive methods. The researchers have reported the IN-1k top-1 accuracy for options extracted from the final layer in comparison with the layer with the very best efficiency.
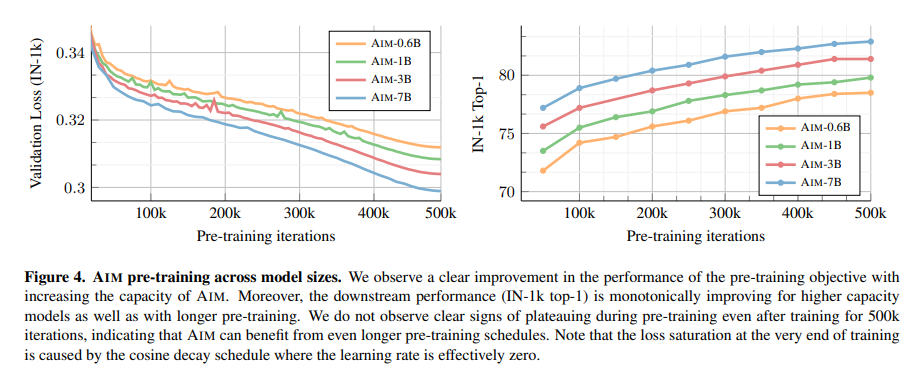
In conclusion, The researchers have launched a easy and scalable unsupervised pre-training technique, AIM, using a generative autoregressive goal. AIM demonstrates easy scaling to 7 billion parameters with out advanced stability-inducing strategies. Its sturdy correlation between pre-training and downstream efficiency, coupled with spectacular outcomes throughout 15 benchmarks, outperforming prior state-of-the-art strategies, underscores its efficacy. There’s potential for additional enhancements with bigger fashions and longer coaching schedules, positioning AIM as a basis for future analysis in scalable imaginative and prescient fashions leveraging uncurated datasets with out bias.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.

