Avatar expertise has grow to be ubiquitous in platforms like Snapchat, Instagram, and video video games, enhancing person engagement by replicating human actions and feelings. Nevertheless, the hunt for a extra immersive expertise led researchers from Meta and BAIR to introduce “Audio2Photoreal,” a groundbreaking technique for synthesizing photorealistic avatars able to pure conversations.
Think about participating in a telepresent dialog with a buddy represented by a photorealistic 3D mannequin, dynamically expressing feelings aligned with their speech. The problem lies in overcoming the constraints of non-textured meshes, which fail to seize delicate nuances like eye gaze or smirking, leading to a robotic and uncanny interplay (see Determine 1, center). The analysis goals to bridge this hole, presenting a technique for producing photorealistic avatars based mostly on the speech audio of a dyadic dialog.
The strategy includes synthesizing numerous high-frequency gestures and expressive facial actions synchronized with speech. Leveraging each an autoregressive VQ-based technique and a diffusion mannequin for physique and palms, the researchers obtain a stability between body fee and movement particulars. The result’s a system that renders photorealistic avatars able to conveying intricate facial, physique, and hand motions in actual time.
To help this analysis, the workforce introduces a singular multi-view conversational dataset, offering a photorealistic reconstruction of non-scripted, long-form conversations. In contrast to earlier datasets centered on higher physique or facial movement, this dataset captures the dynamics of interpersonal conversations, providing a extra complete understanding of conversational gestures.

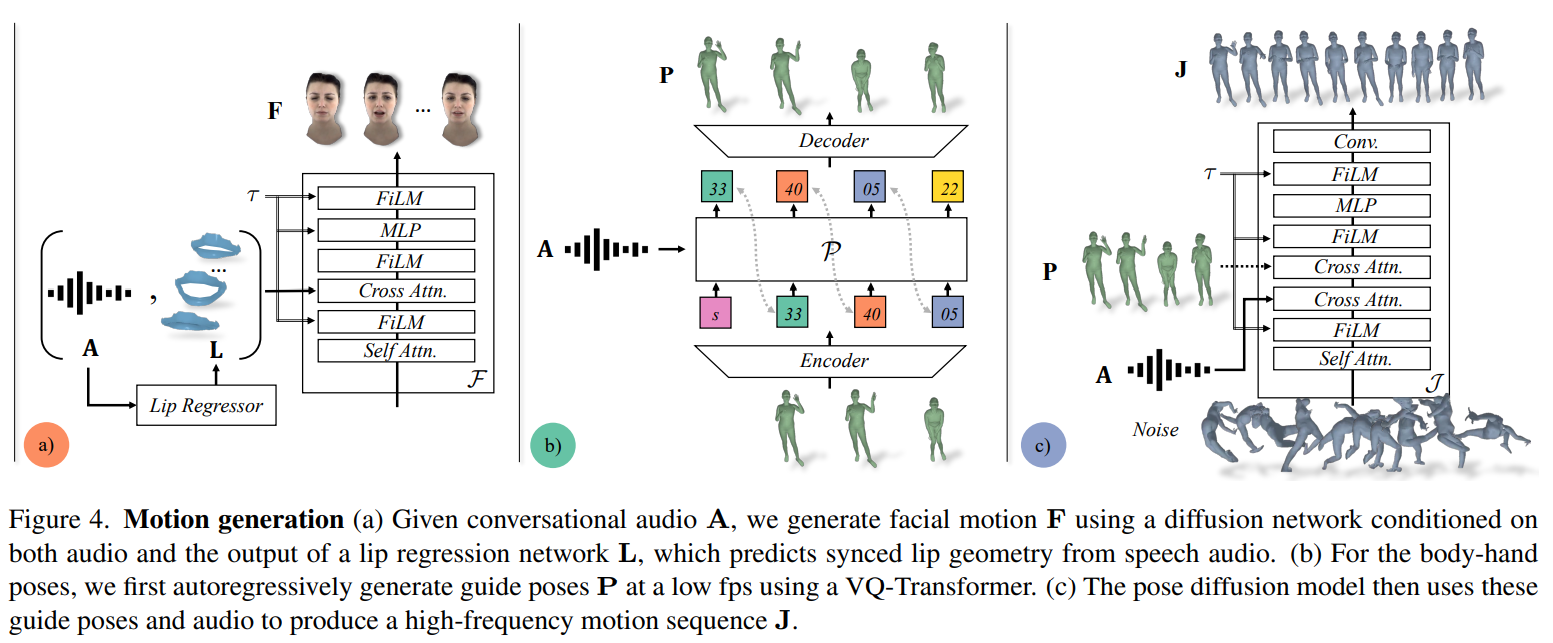
The system employs a two-model (proven in Determine 3) strategy for face and physique movement synthesis, every addressing the distinctive dynamics of those elements. The face movement mannequin (Determine 4(a)), a diffusion mannequin conditioned on enter audio and lip vertices, focuses on producing speech-consistent facial particulars. In distinction, the physique movement mannequin makes use of an autoregressive audio-conditioned transformer to foretell coarse information poses (Determine 4(b)) at 1fps, later refined by the diffusion mannequin (Determine 4(c)) for numerous but believable physique motions.

The analysis demonstrates the mannequin’s effectiveness (proven in Determine 6) in producing life like and numerous conversational motions, outperforming numerous baselines. Photorealism proves essential in capturing delicate nuances, as highlighted in perceptual evaluations. The quantitative outcomes showcase the tactic’s potential to stability realism and variety, surpassing prior works when it comes to movement high quality.
Whereas the mannequin excels in producing compelling and believable gestures, it operates on short-range audio, limiting its functionality for long-range language understanding. Moreover, the moral concerns of consent are addressed by rendering solely consenting individuals within the dataset.

In conclusion, “Audio2Photoreal” represents a big leap in synthesizing conversational avatars, providing a extra immersive and life like expertise. The analysis not solely introduces a novel dataset and methodology but additionally opens avenues for exploring moral concerns in photorealistic movement synthesis.
Take a look at the Paper and Venture. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s keen about analysis and the most recent developments in Deep Studying, Pc Imaginative and prescient, and associated fields.